SQL语句性能分析工具 - explain
通过explain,如以下例子:
1 | EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26'; |
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | filtered | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | titles | null | const | PRIMARY | PRIMARY | 59 | const,const,const | 10 | 1 |
id:在⼀个⼤的查询语句中每个SELECT关键字都对应⼀个唯⼀的id ,如
explain select * from s1 where id = (select id from s1 where name = 'egon1');第一个select的id是1,第二个select的id是2。
有时候会出现两个select,但是id却都是1,
这是因为优化器把子查询变成了连接查询 。
select_type:select关键字对应的那个查询的类型,如
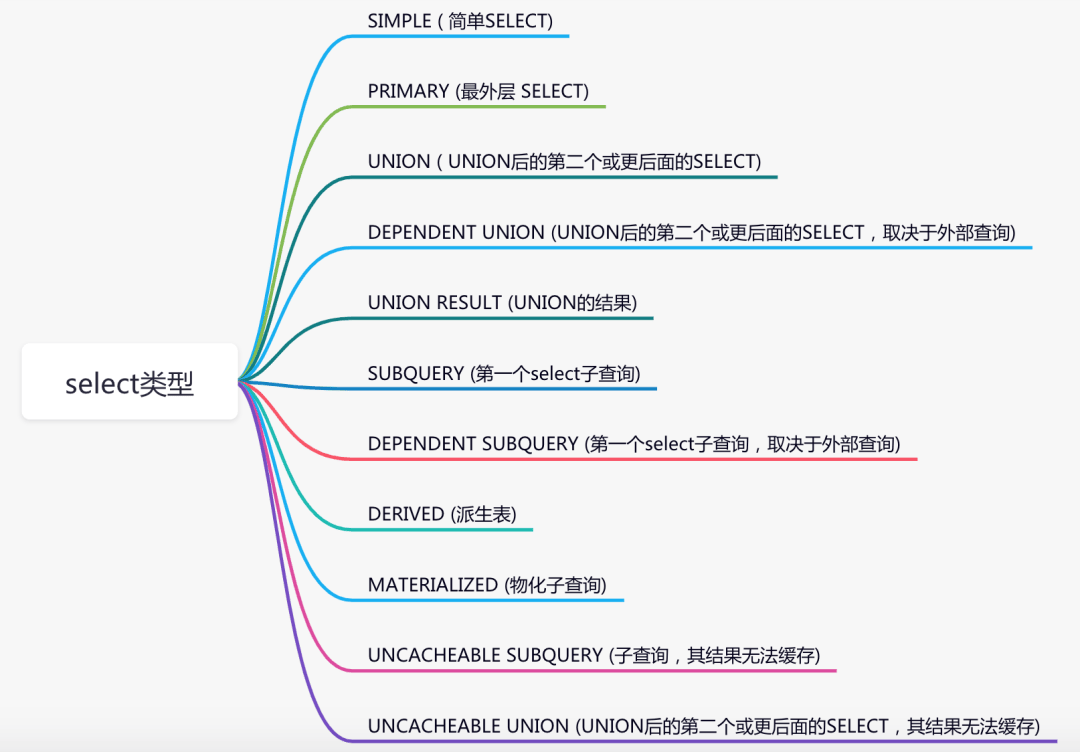
类型 含义 SIMPLE 简单SELECT查询,不包含子查询和UNION PRIMARY 复杂查询中的最外层查询,表示主要的查询 SUBQUERY SELECT或WHERE列表中包含了子查询 DERIVED FROM列表中包含的子查询,即衍生 UNION UNION关键字之后的查询 UNION RESULT 从UNION后的表获取结果集 table:每个查询对应的表名
<unionM,N>:具有和id值的行的M并集N。<derivedN>:用于与该行的派生表结果id的值N。派生表可能来自(例如)FROM子句中的子查询 。<subqueryN>:子查询的结果,其id值为N
partitions:该列的值表示查询将从中匹配记录的分区
type:
type字段比较重要, 它提供了判断查询是否高效的重要依据依据.通过
type字段, 我们判断此次查询是全表扫描还是索引扫描等。如const(主键索引或者唯一二级索引进行等值匹配的情况下);
ref(普通的⼆级索引列与常量进⾏等值匹配);
index(扫描全表索引的覆盖索引) …
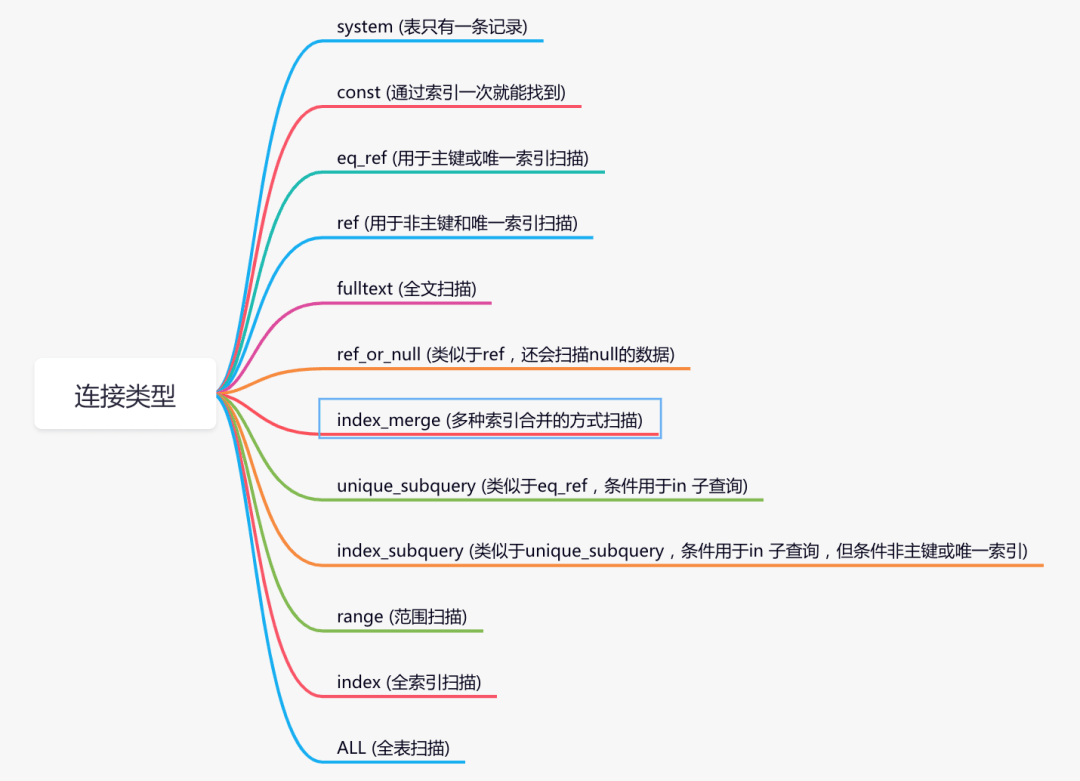
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
通常来说, 不同的 type 类型的性能关系如下:
ALL < index < range ~ index_merge < ref < eq_ref < const < systemALL类型因为是全表扫描, 因此在相同的查询条件下, 它是速度最慢的.而index类型的查询虽然不是全表扫描, 但是它扫描了所有的索引, 因此比 ALL 类型的稍快.possible_key:查询中可能用到的索引(可以把用不到的删掉,降低优化器的优化时间)
key:此字段是 MySQL 在当前查询时所真正使用到的索引。
key_len:该列表示使用索引的长度。
ref:该列表示索引命中的列或者常量。
rows 也是一个重要的字段. MySQL 查询优化器根据统计信息, 估算 SQL 要查找到结果集需要扫描读取的数据行数.这个值非常直观显示 SQL 的效率好坏, 原则上 rows 越少越好。
filtered:查询器预测满足下一次查询条件的百分比 。
extra:表示额外信息,如Using where,Start temporary,End temporary,Using temporary等。
枚举值 涵义 Impossible WHERE 表示WHERE后面的条件一直都是false Using filesort 表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现 Using index 表示是否用了覆盖索引,说白了它表示是否所有获取的列都走了索引 Using temporary 表示是否使用了临时表,一般多见于order by 和 group by语句 Using where 表示使用了where条件过滤 Using join buffer 表示是否使用连接缓冲 No tables used Query语句中使用from dual 或不含任何from子句 Select tables optimized away 这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
常用的字符编码占用字节数量如下:
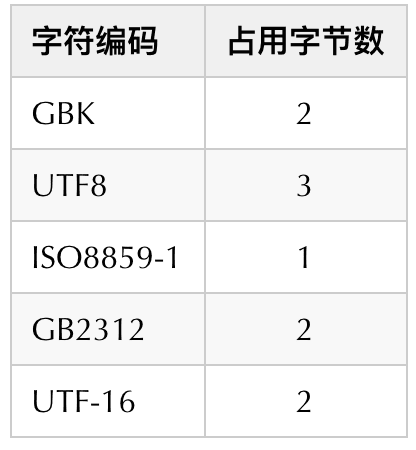
目前我的数据库字符编码格式用的:UTF8占3个字节。
MySQL常用字段占用字节数:
| 字段类型 | 占用字节数 |
|---|---|
| char(n) | n |
| varchar(n) | n + 2 |
| tinyint | 1 |
| smallint | 2 |
| int | 4 |
| bigint | 8 |
| date | 3 |
| timestamp | 4 |
| datetime | 8 |
使用explain命令,查看MySQL的执行计划。
| 项目 | 释义 |
|---|---|
| id | select唯一标识 |
| select_type | select类型 |
| table | 表名称 |
| partitions | 匹配的分区 |
| type | 连接类型 |
| possible_keys | 可能的索引选择 |
| key | 实际用到的索引 |
| key_len | 实际索引长度 |
| ref | 与索引比较的列 |
| rows | 预期要检查的行数 |
| filtered | 按表条件过滤的行百分比 |
| extra | 附加信息 |
索引优化的过程
先用慢查询日志定位具体需要优化的sql
使用explain执行计划查看索引使用情况
重点关注:
key(查看有没有使用索引)
key_len(查看索引使用是否充分)
type(查看索引类型)
extra(查看附加信息:排序、临时表、where条件为false等)
一般情况下根据这4列就能找到索引问题。
根据上1步找出的索引问题优化sql
再回到第2步





