Kafka
使用kafka可以对系统
解耦、
流量削峰、
缓冲
可以实现系统间的异步通信等。
在活动追踪、消息传递、度量指标、日志记录和流式处理等场景中非常适合使用kafka。
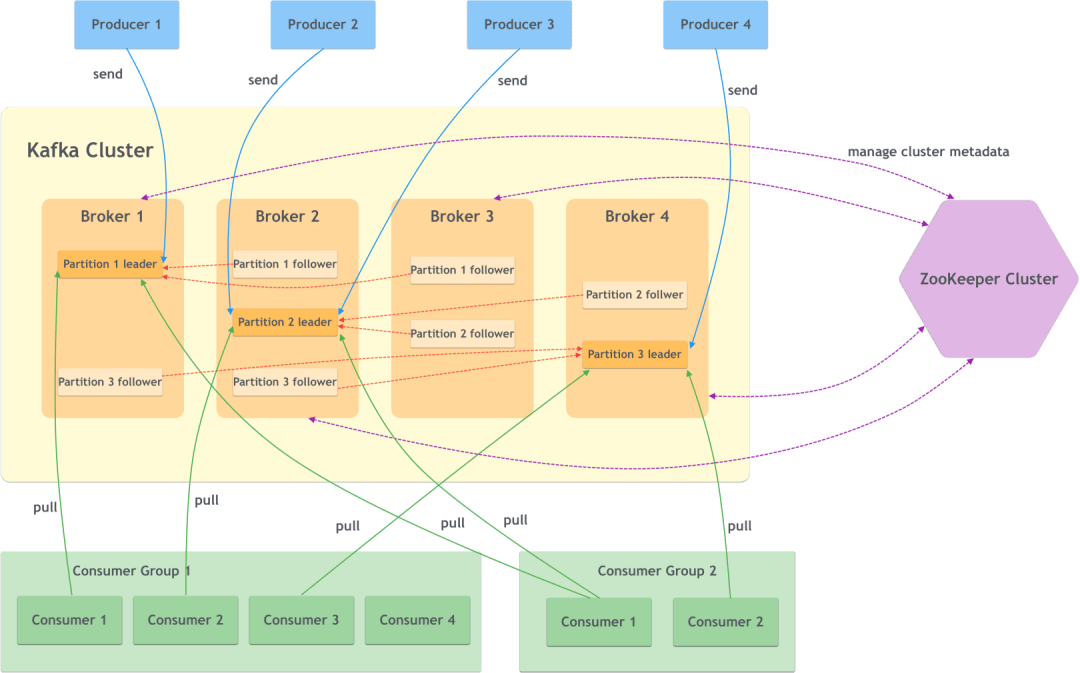
| 组件 | 释义 | 备注 |
|---|---|---|
| Broker | 服务代理节点 | 其实就是一个kafka实例或服务节点,多个broker构成了kafka cluster |
| Producer | 生产者 | 也就是写入消息的一方,将消息写入broker中 |
| Consumer | 消费者 | 也就是读取消息的一方,从broker中读取消息 |
| Consumer Group | 消费组 | 一个或多个消费者构成一个消费组,不同的消费组可以订阅同一个主题的消息且互不影响 |
| ZooKeeper | kafka使用zookeeper来管理集群的元数据,以及控制器的选举等操作 | |
| Topic | 主题 | 每一个消息都属于某个主题,kafka通过主题来划分消息,是一个逻辑上的分类。 |
| Partition | 分区 | 同一个主题下的消息还可以继续分成多个分区,一个分区只属于一个主题 |
| Replica | 副本 | 一个分区可以有多个副本来提高容灾性。 |
| Leader and Follower | 主从 | 分区有了多个副本,那么就需要有同步方式。kafka使用一主多从进行消息同步,主副本提供读写的能力,而从副本不提供读写,仅仅作为主副本的备份。 |
| Offset | 偏移 | 分区中的每一条消息都有一个所在分区的偏移量,这个偏移量唯一标识了该消息在当前这个分区的位置,并保证了在这个分区的顺序性,不过不保证跨分区的顺序性。 |
简单来说,作为消息系统的kafka本质上还是一个数据系统。既然是一个数据系统,那么就要解决两个根本问题:
当我们把数据交给kafka的时候,kafka怎么存储;
当我们向kafka要回数据的时候,kafka怎么返回。

目前大多数数据系统将数据存储在磁盘的格式有追加日志型以及B+树型。而kafka采用了追加日志的格式将数据存储在磁盘上,整体的结构如下图:
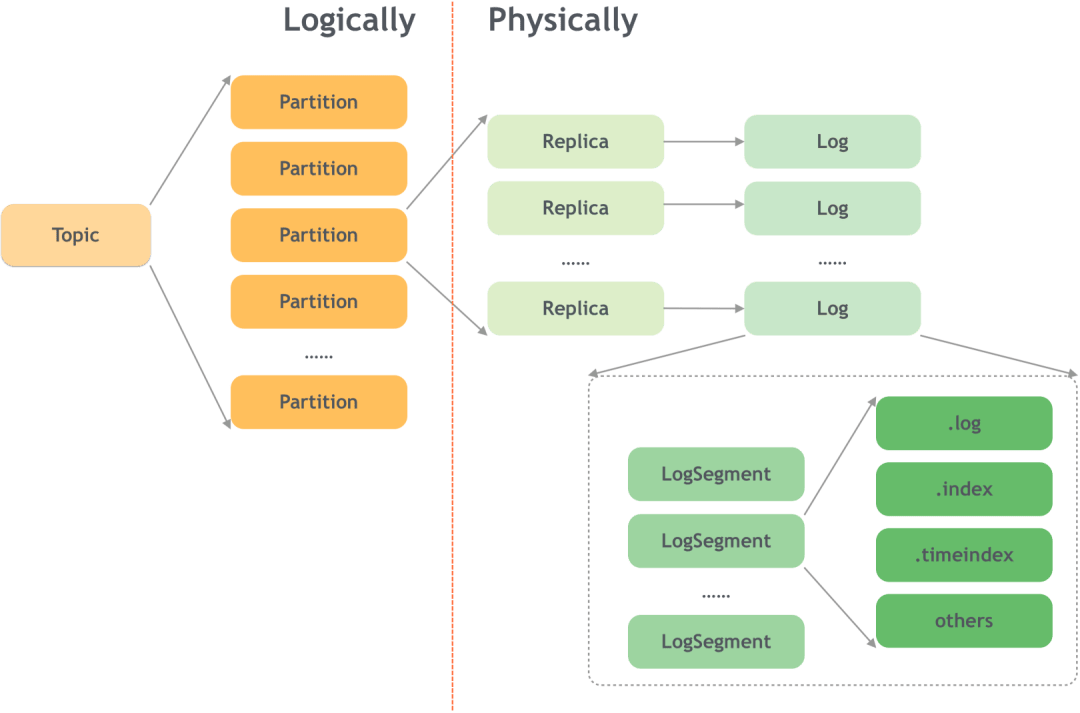
追加日志的格式可以带来写性能的提升(毕竟只需要往日志文件后面追加就可以了),但是同时对读的支持不是很友好。为了提升读性能,kafka需要额外的操作。
关于kafka的数据是如何存储的是一个比较大的问题,这里先从逻辑层面开始。
Topic+Partition的两层结构
Offset
发送方式
消息的发送有三种方式:
发后即忘(fire and forget):只管发送不管结果,性能最高,可靠性也最差;
同步(sync):等集群确认消息写入成功再返回,可靠性最高,性能差很多;
异步(async):指定一个callback,kafka返回响应后调用来实现异步发送的确认。
其中前两个是同步发送,后一个是异步发送。不过这里的异步发送没有提供callback的能力。
那么生产者发送消息之后kafka怎么才算确认呢?这涉及到acks参数:
acks = 1, 默认值1,表示只要分区的leader副本成功写入就算成功;
acks=0,生产者不需要等待任何服务端的响应,可能会丢失数据;
acks=-1或acks=all,需要全部处于同步状态的副本确认写入成功,可靠性最强,性能也差。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Michael's Blog!
相关推荐

2019-03-20
MQ面试经
为什么使用消息队列?消息队列的优点和缺点?kafka、activemq、rabbitmq、rocketmq都有什么优缺点? 面试官角度分析: (1)你知不知道你们系统里为什么要用消息队列这个东西? (2)既然用了消息队列这个东西,你知不知道用了有什么好处? (3)既然你用了MQ,那么当时为什么选用这一款MQ? 1. 为什么使用消息队列?面试官问这个问题的期望之一的回答是,你们公司有什么业务场景,这个业务场景有什么技术挑战,如果不用MQ可能会很麻烦,但是再用了之后带来了很多好处。 消息队列的常见使用场景有很多但是核心的有三个:解耦、异步、削峰 解耦场景描述:A系统发送个数据到BCD三个系统,接口调用发送,那如果E系统也要这个数据呢?那如果C系统现在不需要了呢?现在A系统又要发送第二种数据了呢?A系统负责人崩溃中…再来点崩溃的事儿,A系统要时时刻刻考虑BCDE四个系统如果挂了怎么办?那我要不要重发?我要不要把消息存起来?头发都白了啊… 使用了MQ之后的解耦场景 面试技巧:你需要考虑下,你负责的系统中是否有类似的场景,就是一个系统或者一个模块,调用了多个系统或者模块,相互之间的调用...

2019-03-20
MQ
转自 特性 ActiveMQ RabbitMQ RocketMQ Kafka 单机吞吐量 万级,比 RocketMQ、Kafka 低一个数量级 同 ActiveMQ 10 万级,支撑高吞吐 10 万级,高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 topic 数量对吞吐量的影响 topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic topic 从几十到几百个时候,吞吐量会大幅度下降,在同等机器下,Kafka 尽量保证 topic 数量不要过多,如果要支撑大规模的 topic,需要增加更多的机器资源 时效性 ms 级 微秒级,这是 RabbitMQ 的一大特点,延迟最低 ms 级 延迟在 ms 级以内 可用性 高,基于主从架构实现高可用 同 ActiveMQ 非常高,分布式架构 非常高,分布式,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 消息可靠性 有较低的概率丢失数据 基本不丢 经过参数优化配置,可以做到 0 丢失...
评论

